
جلسه دفاع پایان نامه کارشناسی ارشد (آقای پویان شفاعت)
موضوع: یادگیری تقویتی عمیق ربات دوپا جهت راه رفتن روی سطح شیبدار با استفاده از بهینهسازی سیاست مجاورتی
ارائه دهنده: پویان شفاعت
استاد راهنما: دکتر محمد دانش
استادان داور: دکتر سعید بهبهانی- دکتر مهدی کاروان
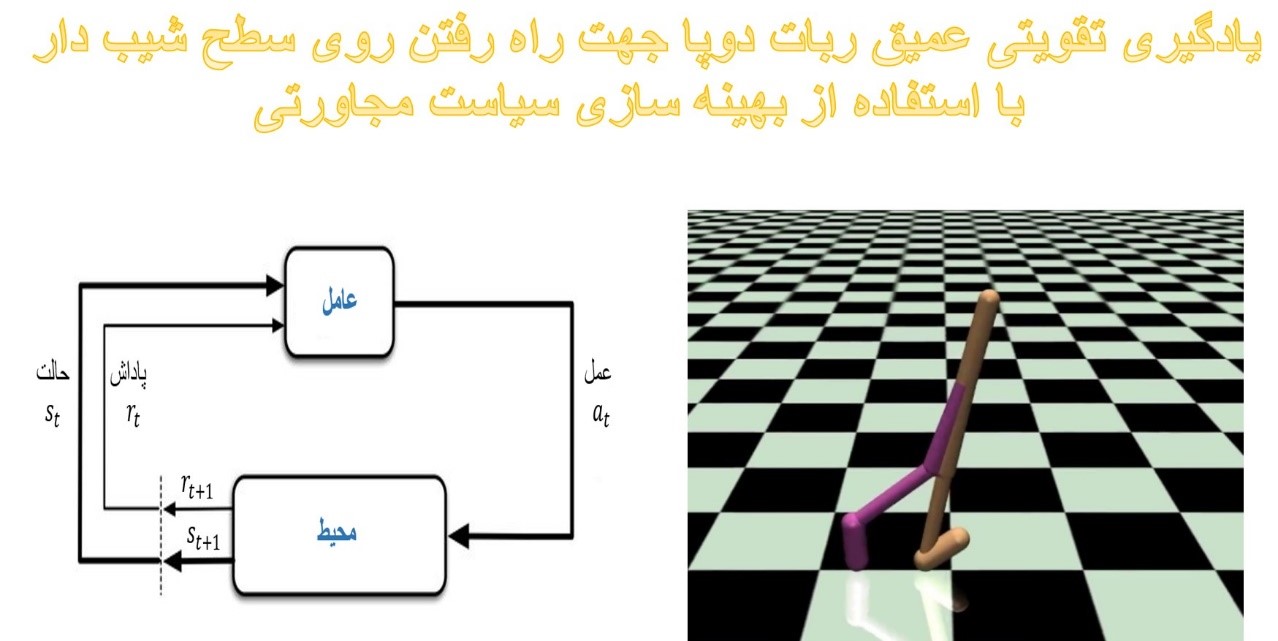
چکيده:
پیشرفتهای اخیر در زمینه یادگیری تقویتی قابلیتهای امیدوارکننده این روش را در حوزه کنترل ربات نشان داده است. این پژوهش پس از مرور الگوریتمهای نوین یادگیری تقویتی، یکی از این الگوریتمها را جهت کنترل هوشمند حرکت ربات به کار میگیرد. روشهای کلاسیک جهت کنترل ربات نیاز به خبرگی زیادی دارد و همینطور به سختی قابل پیادهسازی هستند. این روشها دقت بالایی دارند، اما در مقابل روشهای یادگیری تقویتی عمیق تعمیمپذیر هستند و نسبت به تغییر محیط مسئله قوام خوبی ارائه میدهند. در این پژوهش یکی از محیطهای جیم موجوکو به نام Walker-2d مورد آزمایش قرار گرفت و الگوریتم بهینهسازی سیاست مجاورتی روی آن پیادهسازی شد. هدف از انجام این آزمایش آموزش راه رفتن به ربات روی شیبهای مختلف بود. مشخص شد که ربات دوپا قابلیت راه رفتن روی شیبهای مختلف را تنها با تغییر در تابع پاداش پیدا کرد. همچنین به علاوه نتایج ذکر شده، پس از آموزش ربات روی هر شیب، اقدام به آزمایش مدلهای از قبل آموزش دیده شد. در این آزمایش هر کدام از مدلها روی چند شیب مختلف امتحان شدند و مشخص شد بر خلاف انتظار، ربات هنوز تا حدودی قادر به راه رفتن بود. این آزمایش قوام بیشتر این روش را نشان داد.
